Introducción a la Cardinalidad en Bases de Datos
La cardinalidad en bases de datos es un concepto fundamental que se refiere a la naturaleza de las relaciones entre las tablas. En términos simples, define cuántas entidades de un conjunto pueden estar asociadas con entidades de otro conjunto. La cardinalidad puede ser mínima o máxima, y este par de valores determina las restricciones y reglas que guían estas relaciones.
¿Qué indica la Cardinalidad?
La cardinalidad mínima indica el número mínimo de veces que una entidad puede participar en una relación. Por ejemplo, si una relación entre dos tablas tiene una cardinalidad mínima de cero, esto significa que una entidad puede existir sin estar relacionada con ninguna entidad del otro conjunto. Por otro lado, la cardinalidad máxima representa el número máximo de veces que una entidad puede participar en una relación. Este valor podría ser uno, muchos, o cualquier número definido como límite.
Ejemplo sencillo: Entidad estudiante y curso
Consideremos un ejemplo sencillo: una relación entre las tablas de «Estudiantes» y «Cursos». Si un estudiante puede inscribirse en varios cursos, pero cada curso puede tener muchos estudiantes, la cardinalidad entre estas dos tablas sería de «muchos a muchos» (n:m). Por el contrario, si un curso solo puede ser impartido por un profesor, pero un profesor puede impartir varios cursos, la relación entre «Profesores» y «Cursos» sería de «uno a muchos» (1:n).
La correcta definición de la cardinalidad es crucial ya que impacta directamente en la integridad y eficiencia de una base de datos. Una cardinalidad mal definida puede llevar a problemas de redundancia de datos, dificultades en la recuperación de información y errores de integridad referencial. Por lo tanto, comprender y aplicar adecuadamente los diferentes tipos de cardinalidad es esencial para diseñar sistemas de bases de datos que sean tanto robustos como eficientes.
🌟 ¡Visita Nuestra Tienda para Programadores! 🌟Descubre Códigos Fuente, Cursos, Software, Computadoras, Accesorios y Regalos Exclusivos. ¡Todo lo que necesitas para llevar tu programación al siguiente nivel!
Tipos de Cardinalidad en Bases de Datos
Cardinalidad Uno a Uno (1:1)
La cardinalidad uno a uno (1:1) en bases de datos se refiere a una relación en la cual cada fila de una tabla está asociada con una única fila de otra tabla. Este tipo de relación es menos común en comparación con otros tipos de cardinalidad, como uno a muchos (1:N) o muchos a muchos (M:N), pero es esencial en situaciones donde se necesita una correspondencia estricta entre dos conjuntos de datos.
Ejemplo de cardinalidad 1:1 en base de datos
Un ejemplo práctico de la cardinalidad 1:1 es la relación entre una tabla de ‘Usuarios’ y una tabla de ‘Perfiles de Usuario’. En este escenario, cada usuario tiene un único perfil asociado, y cada perfil pertenece únicamente a un usuario. Esto se puede implementar mediante claves primarias y foráneas, asegurando que cada registro en la tabla de ‘Usuarios’ tenga un correspondiente registro en la tabla de ‘Perfiles de Usuario’.

La relación uno a uno se establece mediante la clave foránea UsuarioID en la tabla Perfiles, que referencia al UsuarioID en la tabla Usuarios y es única para asegurar la relación uno a uno.
Ventajas de la cardinalidad 1:1 en base de datos
Las ventajas de utilizar una relación de cardinalidad uno a uno incluyen la posibilidad de dividir datos en tablas más manejables y especializadas, lo que puede mejorar el rendimiento y la organización de la base de datos. Además, este enfoque facilita el mantenimiento de la integridad referencial, dado que cada entrada en una tabla está directamente vinculada a una entrada en otra tabla.
Aspectos a tener en cuenta de esta cardinalidad
No obstante, existen desventajas asociadas con la cardinalidad 1:1. Una de las principales es la sobrecomplicación innecesaria del esquema de la base de datos cuando no es realmente necesario dividir la información en dos tablas. Esto puede llevar a un diseño más complejo sin beneficios tangibles en términos de rendimiento o mantenimiento. Además, la implementación de este tipo de relación puede requerir más operaciones de unión (JOIN), lo que podría afectar negativamente al rendimiento en consultas complejas.
En el diseño de bases de datos, es crucial evaluar cuándo utilizar una relación de cardinalidad uno a uno. Este tipo de cardinalidad es más apropiado en situaciones donde los datos en cuestión tienen una relación naturalmente única y excluyente, como en el caso de información sensible o datos que requieren segregación por razones de seguridad o privacidad.
Cardinalidad Uno a Muchos (1:N)
En el ámbito de las bases de datos, la cardinalidad uno a muchos (1:N) es un tipo de relación fundamental que define cómo una fila de una tabla puede estar vinculada con múltiples filas de otra tabla. Este tipo de cardinalidad es comúnmente observado en escenarios como la relación entre una tabla de ‘Autores’ y una tabla de ‘Libros’. En este ejemplo, un autor puede escribir varios libros, lo que significa que una única entrada en la tabla de ‘Autores’ puede estar relacionada con múltiples entradas en la tabla de ‘Libros’.
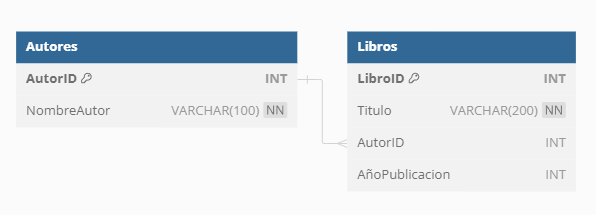
La relación uno a muchos se establece mediante la clave foránea AutorID en la tabla Libros, lo que permite que un autor tenga múltiples libros, pero cada libro tiene un solo autor.
A tener en cuenta con esta cardinalidad 1:N en base de datos
La implementación de la cardinalidad uno a muchos en el diseño de bases de datos implica una serie de consideraciones importantes. Primero, es esencial manejar adecuadamente las claves foráneas para mantener la integridad referencial. En nuestro ejemplo, la tabla de ‘Libros’ tendría una clave foránea que referenciaría la clave primaria de la tabla de ‘Autores’. Esto asegura que cada libro esté asociado con un autor específico, evitando problemas de datos inconsistentes.
Además, las consultas SQL deben ser diseñadas eficientemente para optimizar el rendimiento de la base de datos. Por ejemplo, si deseamos obtener todos los libros escritos por un autor específico, una consulta SQL típica podría ser:
SELECT * FROM Libros WHERE autor_id = 1;
Esta consulta selecciona todas las filas de la tabla ‘Libros’ donde la clave foránea autor_id coincide con el identificador del autor deseado. Las consultas que involucren relaciones uno a muchos pueden beneficiarse del uso de índices en las columnas de claves foráneas, lo cual mejora el tiempo de respuesta de las consultas.
Las implicaciones de la cardinalidad uno a muchos también se extienden a la integridad y la normalización de los datos. Mantener la base de datos normalizada ayuda a reducir la redundancia y facilita el mantenimiento de datos precisos y consistentes. En resumen, comprender y aplicar correctamente la cardinalidad uno a muchos es crucial para un diseño de base de datos eficiente y robusto.
Cardinalidad Muchos a Muchos (M:N)
En el ámbito de las bases de datos, la cardinalidad muchos a muchos (M:N) es un tipo de relación en la que varias filas de una tabla pueden estar relacionadas con varias filas de otra tabla. Esta configuración es común en numerosos escenarios, como la relación entre ‘Estudiantes’ y ‘Cursos’, donde un estudiante puede estar inscrito en múltiples cursos y un curso puede tener varios estudiantes. Para implementar este tipo de relación, es necesario crear una tabla intermedia o de unión, que permita gestionar las asociaciones entre las tablas principales.

La tabla Estudiantes_Cursos es una tabla intermedia que establece la relación muchos a muchos entre estudiantes y cursos. Esta tabla contiene claves foráneas EstudianteID y CursoID que referencian a las tablas Estudiantes y Cursos respectivamente, y una clave primaria compuesta por ambas columnas (EstudianteID, CursoID).
Con la cardinalidad N:M Nace una tabla intermedia
La tabla intermedia actúa como un puente entre las dos tablas principales. Por ejemplo, en el caso de ‘Estudiantes’ y ‘Cursos’, la tabla intermedia podría llamarse ‘Estudiantes_Cursos’. Esta tabla suele contener al menos dos columnas: una columna para la clave primaria de la tabla ‘Estudiantes’ y otra para la clave primaria de la tabla ‘Cursos’. De este modo, se establece una relación muchos a muchos entre las dos tablas a través de la tabla intermedia.
Suscríbete y aprende más de bases de datos¿Por qué es importante esta tabla intermedia?
El diseño de la tabla intermedia es fundamental para el rendimiento y la eficiencia de la base de datos. Se recomienda definir índices en las columnas que representan las claves primarias de las tablas principales, lo cual optimiza las consultas y las operaciones de unión. Además, es importante considerar la integridad referencial, utilizando claves foráneas para asegurar que los registros en la tabla intermedia correspondan a registros válidos en las tablas principales.
Ejemplo de cardinalidad N:M en bases de datos
Un ejemplo práctico puede ilustrar mejor el concepto. Supongamos que tenemos una tabla ‘Estudiantes’ con los siguientes campos: ‘ID_Estudiante’, ‘Nombre’, y ‘Apellido’. Asimismo, una tabla ‘Cursos’ con los campos: ‘ID_Curso’, ‘Nombre_Curso’, y ‘Descripción’. La tabla intermedia ‘Estudiantes_Cursos’ tendría las columnas ‘ID_Estudiante’ y ‘ID_Curso’. Cada registro en esta tabla intermedia representa una inscripción específica de un estudiante en un curso particular.
A tener en cuenta en la cardinalidad en bases de datos N:M
Consideraciones de rendimiento también son cruciales al manejar relaciones muchos a muchos. A medida que crece el volumen de datos, es esencial optimizar las consultas y las uniones para mantener el rendimiento de la base de datos. Utilizar índices apropiados y técnicas como la normalización puede ayudar a gestionar eficazmente estas relaciones complejas.
Tipos de bases de datos
Complementa los conocimientos adquiridos en este artículo con el siguiente vídeo!